-
논문 리뷰) ModernBert: Smarter, Better, Faster, Longer A Modern Bidirectional Encoder for Fast Memory Efficent and Long Context Finetuning and InferenceAI 논문 리뷰 2025. 3. 5. 19:23
[총평]
- 논문 제목처럼 더 빠르고, Context Length도 길어지고, 성능도 좋아진 인코더 모델의 등장
- LLM 등에 적용된 최신 기법들(RoPE, Flash-Attention, Alter Attention 등)을 인코더 모델에 적용
- 최신 데이터로 사전학습된 이점
- 단, 영어 위주로 학습된 것과 학습데이터가 공개되지 않은 아쉬움.
- Answer.AI와 LightOn에서 개발한 모델 (아파치 2.0 라이센스)ModernBERT에 어떠한 기법과 모델 구성요소가 적용되었는지를 위주로 확인해보자.
[아키텍쳐 관점에서의 개선] (2.1 Architectural Improvements)
1. 모델 구성요소
- Bias Term
- RoPE
- Pre-Normalization
- GeGLU
2. 연산 효율을 위한 구성요소 외 데이터 처리 기법
- Alternation Attention
- Unpadding
- Sequence Packing[Bias Term]
- 모든 선형(Linear) 레이어에서 바이어스 항을 비활성화(최종 Layer는 유지).
- 모든 LayerNorm에서도 바이어스 항을 제거(Understanding and improving layer normalization 논문을 참조하였다고 함.)
- 이 2가지 변경을 통해, 제한된 파라미터 예산을 보다 중요한 선형 레이어에 집중적으로 사용할 수 있도록 설계.[RoPE]
- 기존의 절대 위치 인코딩 방식은 크게 3가지의 한계가 존재.
- 고정된 위치 정보: Sinusoidal 방식은 위치가 고정된 주기를 가지기 때문에, 상대적인 위치 변화에 대한 유연성이 부족함.
- 범위 확장성 부족: 고정된 주기를 사용하는 경우, max_token을 넘어서는 시퀀스 정보를 처리하기 어려움.
- 상대적인 위치 캡처 부족: 위치 인코딩이 절대적이기 때문에, 토큰 위치 간의 상대적인 관계를 캡처하기 어려웠음.
- RoPE는 벡터의 회전변환을 활용하여,위치정보를 표현하고 토큰 간의 Relative Position 정보를 효과적으로 학습하고자 함.
- ROPE는 주기가 반복되는 방식이기 때문에, 훈련 데이터에서 본 적이 없는 긴 시퀀스에 대해서도 잘 일반화할 수 있음.*행렬 곱 = 벡터의 회전변환
더보기
출처 : wikipedia 
- Transformer의 수백/수천 차원을 2차원씩 pairing하여, 회전변환
- 이를 통해, 차원간 세밀한 표현 또는 보다 차원간 독립적인 표현이 가능하도록 함.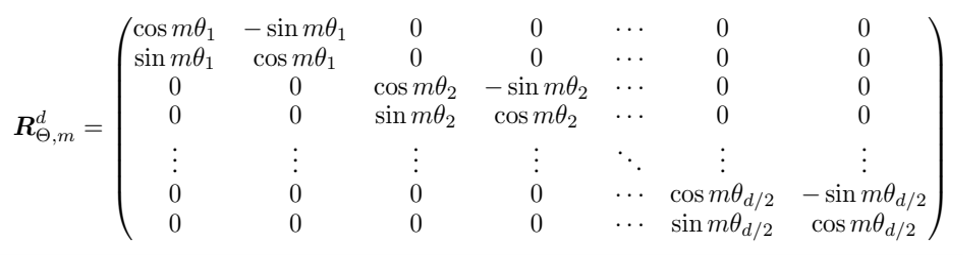
ROPE 논문 그림 - 벡터 내 차원의 순서를 고려 (아래 그림 빨강 1번)
- Text(시퀀스) 내 토큰의 순서를 고려 (아래 그림 빨강 2번)
- 1. 시퀀스에서 뒤쪽에 위치할수록 회전 각도를 증가시킴
2. 차원 Pair 마다 서로 다른 각속도를 부여(낮은 차원 Pair는 빠르게, 높은 차원 Pair는 천천히 회전하도록)
=> 이를 통해, 각 토큰의 Hidden State를 위치정보를 반영하면서도 고유 한 값으로 변환

ROPE 논문 그림 [Normalization]
- 임베딩 후에 추가 정규화 레이어를 추가하여 학습을 안정화하고자 함. (Llama2 모델 패밀리에서 사용된 방식)
- 다만, 중복을 피하기 위해 첫 번째 Attention Layer의 LayerNorm은 제거.
*Pre-Normalization 방식의 구조
- Input → LayerNorm → Self-Attention → Residual Connection
- Input → LayerNorm → Feed-Forward Network (FFN) → Residual Connection
- On Layer Normalization in the Transformer Architecture 논문에서는 layer norm 위치에 따른 학습되는 정도를 실험.
- Post layer norm의 경우, output 근처 매개변수의 gradient norm이 크고 불안정해짐. warm-up 없이 큰 학습률을 사용하면,훈련이 불안정해질수 있음. 따라서, 작은 학습률로 진행하거나 warm-up 단계가 필요함.
- Pre layer norm의 경우, warm-up없이 학습률 조정만으로도 빠르게 최적화 수렴.

All you need is attention과 On Layer Normalization in the Transformer Architecture 논문 그림 
post LN과 pre LN [GeGLU]
- GeLU와 GLU가 mix된 GeGLU를 채택.
- GLU 변형(variant)을 사용할 경우 일관된 성능 향상이 나타난다는 최근 연구 결과를 따름.(기존 BERT는 GeLU를 채택)- GELU 함수는 가우시안 분포 기반으로 input 값을 처리하는 활성화 함수.가우시안 분포를 거쳐 더 자연스러운 비선형성을 제공할수 있음.

GLU와 GeGLU 활성화 함수 [Alternation Attention]
- 어텐션 메커니즘이 3개 레이어마다 전체 입력에만 주의를 기울이는 것을 의미(글로벌 어텐션).
- 반면 다른 모든 레이어는 모든 토큰이 가장 가까운 128개 토큰에만 주의를 기울이는 슬라이딩 윈도우를 사용(로컬 어텐션) .
- 이를 통해 긴 입력 시퀀스도 빠르게 처리하도록 함.
출처 : https://huggingface.co/blog/modernbert *Sliding Window Attention
더보기Sliding Window Attention은 각 토큰 주변의 일정 크기(𝑤)의 윈도우 내에서만 Attention을 계산하는 방법.
이 방식에서는 멀리 떨어진 토큰에는 Attention을 적용하지 않고, 인접한 토큰들만 집중적으로 처리.
일반적인 **Self-Attention의 연산 복잡도는 O(𝑛²)**이지만,
**윈도우 방식은 O(𝑛 × 𝑤)**로 줄어들어 선형 복잡도(O(𝑛))에 가까운 성능을 제공.
윈도우 정보를 여러 층(ℓ) 쌓으면 CNN처럼 Receptive Field가 확장되므로,
최종적으로 ℓ × 𝑤 범위까지 문맥 정보를 고려할 수 있는 표현(Representation)이 형성되기를 기대할수 있음.
윈도우 내에서만 Attention을 수행하므로, 로컬 문맥을 더 세밀하게 반영. (대신, Long context 놓칠 확률높아짐.)
Longformer 논문 설명 자료 [Flash Attention]
- 메모리(HBM 등) 엑세스를 줄이는 것이 근본 철학.
- 이를 위해 cache 안에 변수를 저장하고 cache 변수로 최대한 계산할수 있는 부분은 모두 계산하는 것이 아이디어.
- 모델 개발시, Flash Attention 3은 Sliding Window Attention을 지원하지 않아 아래처럼 계층별로 FA 버젼을 달리 적용.
a) Global(Full) Attention → Flash Attention 3 사용
b) Local(Sliding Window) Attention → Flash Attention 2 사용[Unpadding] & [Sequence Packing]
- 연산 효율을 위해, Padding을 제거
- 기존에는 모델이 시퀀스를 처리하는 동안 여러번 Unpadding과 Repadding을 반복했으나,
ModernBERT에서는 Flash Attention에서 variable length attention과 RoPE(Rotary Positional Embedding)가 지원되는 것을 적극 활용하여 단 한 번의 언패딩만 수행하도록 함. (필요할 경우, 처리 후 선택적으로 Reppading 하도록 함)
- 이를 통해 10~20% 속도 향상
- torch 레벨에서 다음과 같은 접근으로 구현된 것으로 보임(https://github.com/Dao-AILab/flash-attention/issues/654)
- 연산 효율을 위해, Sequence Packing을 도입 (Unpadding과 짝꿍이라고 봐야)
- 개별 문장(시퀀스) n개를 max_token_length에 가까워질때까지 채워넣는 방식.
- 각 어텐션 마스크는 개별 문장을 구분하도록 함.
출처 : https://huggingface.co/blog/modernbert [학습을 위한 데이터 / 세팅] (2.2 Training)
[Data]
-2trillion token size : Primarily English data a from a variety of data sources, including web documents, code, and scientific literature
[Tokenizer]
- modern BPE tokenizer (GPT-NeoX-20B =>(modified)=> OLMo tokenizer =>(modified)=> ModernBert tokenizer)
- OLMo tokenizer는 code-ralted task에서의 성능과 효율을 위해 선택하였음
- Special 토큰 [CLS], [SEP]는 동일
- 50368개의 vocab 사이즈 (RoBERTa/DeBERTa(50265), XLM-RoBERTa (25만))
[Training Setting]
- MLM (We follow the Masked Language Modeling setup used by MosaicBERT)
- use a masking rate of 30 percent, as the original rate of 15 percent has since been shown to be sub-optimal
- Remove NSP(Next-Sentence Prediction)
- StableAdamW optimizer 적용 (AdamW 개선버젼)
- AdamW에, 각 매개변수 별로 Update Clipping을 통해 학습률을 조정하는 방식(Adafactor)을 적용*Adamw
- Learning Rate Schedule : trapezoidal Learning Rate(LR) schedule을 변형하여 활용
- trapezoidal LR은 사다리꼴 모양의 스케쥴링 (Short Warm-up, Long Constant, Short Decay/Annealing)a) large 모델은 2 billion tokens warm-up => 5e-4 contstant for 900 billion tokens => 5e-5 constant for 800 billion
b) base 모델은 3 billion tokens warm-up => 5e-4 contstant for 1700 billion tokens
- 코사인 스케줄링(cosine scheduling)과 유사한 성능을 제공하면서도,특정 체크포인트에서 훈련을 지속할 때 cold restart 문제 없이 자연스럽게 이어서 학습할 수 있는 장점을 갖는다고함.
- 대부분의 trapezoidal LR과 달리, 저자는 1 - sqrt(제곱근) 형태의 학습률 감소 방식을 적용
A Walk with SGD 논문 그림 참조
- Batch Size Schedule :
a) large 모델 : 448 to 4608
b) base 모델 : 768 to 4928
- Weight Initialization and Tiling:
a) large : Phi Model의 과정을 따름.
b) base : Megatron에서 사용한 Randow Weights를 적용
- Context Length Extension:
- 1.7 trillion token은 1024 길이로 RoPE theta 10000으로 학습
- 이후, 추가로 context length 연장을 위해, 8192 길이로 글로벌 어텐션 레이어의 RoPE theta를 160000로 학습.[모델 평가] (3. Evaluation)
- 기존모델 대비 대체적인 성능 우위
- DPR 방식일때, MLDR에서 Large/base 모두 GTE-en-MLM 모델 대비 약세
- ColBERT(멀티벡터 방식: 문서내 토큰별 벡터를 저장)에서는 크게 우위.
- GLUE에서는 DeBERTa V3한테 뒤쳐지는 모습을 보였음.
- 앞도적인 성능 우위라고 보기는 어려워, 도입시 타 모델과의 성능 테스트는 필요해보임
- 그러나, 추론 속도까지 고려했을때 효용성이 높아 보임. 728x90
728x90'AI 논문 리뷰' 카테고리의 다른 글
