-
논문 리뷰) DiffCSE - Difference-based Contrastive Learning for Sentence EmbeddingsAI 논문 리뷰 2024. 5. 23. 23:35
22년에 발표된 DiffCSE는 MLM과 SimCSE를 조합한 방식을 제안하였는데,
특히 Self-prediction 중 Innate relationship prediction을 추가로 활용한 것이 핵심 아이디어다.
( Innate relationship prediction이 무엇인지는 이전 글을 참고하길 바란다)
학습 시에 original 문장의 일부를 마스킹하고, 마스킹 된 부분을 Generator 통해 생성한 뒤,
변형된 전체 문장에서 어느 부분이 마스킹된 것인지 Discriminator를 통해 맞히게 하였다. (GAN을 알고 있다면, 이해가 더 쉬울 것이다)
이렇게 마스킹된 부분을 맞히는 작업을 피드백(Loss 함수)에 반영함으로써,
데이터 증강을 위해 수행한 삭제, 마스킹 등의 행위가 문장 본래의 의미를 잃게하는 것을 보상하고자 하였다.
[배경 설명]
해당 논문은 Equivariant와 invariant에 대해서 중점적으로 다루고, 이에 대한 아이디어를 제안한다.
따라서, Equivariant와 invariant가 무엇인지 알고 넘어가야 한다.
사전적인 뜻은 아래와 같다.
- invariant : 불변의
- equivariant : 동일의아래에 두 용어를 잘 표현한 수식이 있다.
- f(g(x)) = g(f(x)로 바꾸더라도, 두 계산 값이 동일하고 (Equivariant)
- g(x)를 적용하더라도, f(x)와 f(g(x))가 결과가 동일함 (Invariant)
(글로 잘 표현하기 어렵다. 그래도 아래 수식을 받드시 이해하고 넘어가자)

invariant와 equivariant를 표현한 수식 < Invariant >
출처 : https://jrc-park.tistory.com/312 Convolution Neural Network 에서 그 결과물이 동일한 이미지(좌측)이던, 이미지가 아닌 스칼라 값이든지(우측)
1) 윗 케이스는 이미지를 모델에 넣고 Convolutional Representation이 추출됨
2) 아래 케이스는 이미지를 회전 하고 모델에 넣고, Convolutional Representation이 추출됨.
=> 두 Representations 가 동일하다. 따라서, g 함수는 invariant하다.< Eqiuvariant >
출처 : https://jrc-park.tistory.com/312 예시 ) Convolution Neural Network 에서
1) 윗 케이스는, 이미지를 모델에 넣고 Convolutional Representation 을 회전
2) 이미지를 회전을 먼저하고, 그 다음 모델을 통해 Convolutional Representation 획득
두 Representations 가 동일하므로, 주어진 f(x)에 대해 g(x)가 Equivariant하다.위 케이스를 보건대
회전하는 Transformation, 즉 g(x)는 convolution 펑션 f(x)에 대해 Invariant하고 Equivariant하다.좀 더 내츄럴하게 이해하자면, 이미지를 회전하더라도 우리는 그 이미지를 인식할수 있다!!
그러므로 Convolution Representation을 구할때 '회전'이라는 Transformation은 data augment시,
오리지날 data와 동일하게 loss function을 적용할수 있다.
그런데 자연어를 delete하고 replacement하는 augment 펑션도 그러한가?그렇지 않다. 의미가 바뀌기 때문이다.
이 질문에 대한 대답과 해결방안이 본 논문에 대한 핵심 컨셉이다.===========================================
[1. Introduction]
contrastive learnng에서 목적함수는 representation을 잘 할수 있도록,augmented된 transformation에 대해 invariant해야한다.
그러나, 종종 delete, replacement 같은 augmentation은 그 의미를 바꿔버린다. (Invariant하지 않다)
따라서, 의미가 바뀌게 된 augmentation이라면 embedding도 그 의미에 맞게 되어야 이상적이다.
그래서 우리는 'equivariant contrastive learning'이라는 논문에서 제안한 방법을 모사하였다.
해당 방법은 이미지에 대한 transformation 중 sensitive한 것과 insensitive한 것을 나누었고,이에 따라 loss function도 구분하였다.
여기서 sensitive란, transformation시 그 의미도 변질될수 있는 것을 말한다.
[2.2 Equivariant Contrastive learning]
DiffCSE는 'equivariant contrastive learning'이라는 CV쪽 논문에서 제안한 방법을 모사하였다.equivariant contrastive learning의 학습 방식
equivariant contrastive learning에서는 Figure 3.과 같이 새를 좌우 대칭하는 것은 insensitive하고,
새를 회전시키는 것은 Sensitive하다고 보았다.그리고 Sensitive한 Augmentation에는 새의 회전 방향을 맞추게 함으로써
Equivariance를 확보하려고 하였다.
본 논문에서도 마찬가지로
encoder가 MLM augmentation에 대해 equivariant 될 수 있도록 하는 것이 키포인트다.
Mask된 성분에 대해 generate 한 다음,
ELECTRA 모델을 통해 masked-to-generated 된 token이 어떤 것이 맞추는 작업을 하는 것이
encoder가 MLM에 대해 equivarinat해지는 것이라 가정하였다.
[3. Difference-based Contrastive Learning]
Contrastive learning에는 동일하게 SimCSE의 로스펑션을 적용하였다.DiffCSE의 Loss Function
여기에 새롭게 추가된 RTD(Replaced Token Detection) Task에 대한 Loss는
Binary Cross-entropy를 적용하였다.
masked-to-generated token을 맞추었을때와 맞추지 못했을때의 각 토큰별 loss 값을 합산하였다.
이를 그림의 문장으로 예시를 들면, 다음과 같다.RTD(Replaced Token Detection) Task에 대한 Loss Function
그리고 두 Loss 값을 합쳐서 최종 Loss Function으로 적용하였다.
이때, 두 loss 값의 절대적 scale 차이를 고려하여, 람다를 0.005로 함.
(5. Ablation Study에 적힌 내용)
최종 Loss Function
Figure 1.과 같이 h = f(x)에서, h는 임베딩된 벡터를 의미한다.
이때, Discriminator D(x)의 gradient는 backpropagation시,
Figure 1에 나온 그럼치럼 h를 통해 인코더에 대한 backpropagation이 가능해진다.
이를 통해, 인코더 모델은 discriminator가 더 잘 맞출수 있도록
전체 문장에 대한 정보를 임베딩 벡터를 담고자 노력할 것이다. 라고 생각하였다.
학습시에는 Generator는 가중치 fix하였고
학습 후에는 Dicriminator를 버리고 인코더만 사용하였다
Figure 1 [4. Experiment]
encoder로 임베딩 벡터를 뽑을때, [CLS] 토큰을 활용하였고 이에 대해 MLP layer와 BatchNorm을 거치도록 하였다
Discriminator는 인코더와 같은 모델을 적용하였고,
Generator는 좀더 사이즈가 작은 Ditillation된 DistilBERT/RoBERTa를 활용하였다.
[4.2 Data]
비지도 학습을 위한 데이터로는 SimCSE에서 공개한 Wikipedia 크롤링 코드를 활용하였고,여기서 random하게 sampling하였다.
평가 데이터로는
유사도 매기기 평가용으로 STS 데이터셋과 전이학습 평가용으로 SentEval을 활용하였다.
[4.3 Result]
Table 1, 2와 같이 전체적으로 두 문장의 유사도를 평가하는 STS와 전이학습 Task를 얼마나 잘 수행하는지 평가하는 SentEval에서 모두 DiffCSE가 좋은 결과를 보였다.
Table 1 
Table 2 [5. Ablation Study]
RTD loss를 제거한다면, 모델의 loss function은 SimCSE와 같게 될 것이다.
Table 3처럼, RTD loss를 제거하였을때 STS 점수가 많이 안좋아 졌다.반면에 SentEval에 대한 점수는 2% 정도만 감소하였다.

Table 3
Table4처럼 Augmentaion 중에서, 두 Task에 대한 평균 성능을 봤을때 MLM이 제일 나았다.
Table 4
Table5처럼 [CLS] 토큰에 BatchNorm 적용한 것이 더 효과가 좋았다.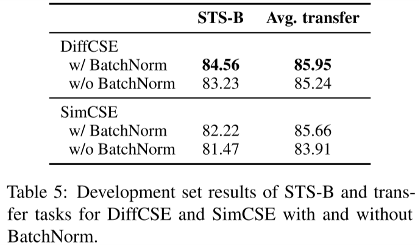
Table 5
Generator는 DistillBert가 가장 효과가 좋았다.
Table 6처럼 Tranfer Task에서 Generator에 따라 성능에 차이는 거의 없었다.
그러나, STS에서 Bert size가 작아질수록 성능이 감소하였다. 이는 ELECTRA에서 얘기한 Generator가 Discriminator의 1/4~1/2일때 가장 성능이 좋았다는 점과는 다른 부분이다.
Table 6
결과적으로 더 강력한 Generator를 쓸수록 Dicriminator의 성능도 좋아졌다.
그러나, 너무 강력한 Generator가 되면 Dicriminator에게 버거운 Task가 될것이므로적당하게 DistilBERT로 실험에 적용하였다.
Contrastive learning loss가 상대적으로 100~1000배 정도 더 작을거라 보고
이에 맞춰 람다 값을 탐색하였고,
Table 8과 같이 0.005일때 Best라는 것을 보였다.

Table 8 [6. Analysis]
Table 9과 같이, MLM task에 힘입어 DiffCSE는 you can do it, too에 대한 유사 문장으로 yes, you can do it을 골랐다.
이에 반해 SimCSE는 문장의 구조만 비슷하고 의미가 다른 you can use it, too를 골랐다.
Table 9
유사도 점수가 5점 만점에 5점인 97개의 positive 문장 쌍을 Retrieval Task 평가에 활용하였다.
Recal@1/5/10으로 평가하였고 결과는 Table 10과 같다.
Table 10
Table 11처럼, SimCSE 대비 DiffCSE는 Uniformity는 감소했지만, Alignment가 크게 올랐다.
따라서, DiffCSE의 향상된 임베딩 성능은 Alignment를 통해서 이뤄졌다고 볼수 있겠다.(Contrastive learning에서, Alignment와 Uniformity이란?)

Table 11 728x90'AI 논문 리뷰' 카테고리의 다른 글
논문 리뷰) Mixtral of Experts (Mixtral 8x7B) (0) 2024.05.25 논문 리뷰) Mistral 7B (0) 2024.05.25 논문 리뷰) Improving Text Embeddings with Large Language Model (0) 2024.05.23 논문 리뷰) GPL - Generative Pseudo Labeling for Unsupervised Domain Adaptation (2) 2024.05.22 논문 리뷰) BGE M3-Embedding : Multi-Lingual, Multi-Functionality, Multi-Granularity (0) 2024.05.21
