-
논문 리뷰) BGE M3-Embedding : Multi-Lingual, Multi-Functionality, Multi-GranularityAI 논문 리뷰 2024. 5. 21. 21:32
본 글은 [Open-Up] 오픈소스 소프트웨어 통합지원센터로부터 지원받아 작성하였습니다.
[Abstract]
dense vector, multi-vector, sparse retrieval 방식 3개를 동시에 활용한 것이 큰 특징이다.
(문장의 의미를 벡터에 투영하는 Dense 벡터, 전체 임베딩 값을 그대로 활용하는 Multi-vector 방식,
그리고 빈도 기반 방식인 BM25를 모두 활용)
input token이 최대 8192까지 가능하다.
또한, self 지식증류를 적용하였다.
self 지식증류는 3개의 검색에 대한 점수를 통합하고 이를 teacher로서 활용하는 방식이다.
그리고 Batch 전략에 대한 tip을 제안하였다.
[1. Introduction]
기존 임베딩 모델의 한계
1) 대부분의 임베딩 모델은 영어에 초점이 맞춰져 있으며,
2) 하나의 검색 기능에 초점이 맞춰져있다. 그러나, 실제 환경에서는 다수의 복합적인 검색 기능을 요구한다.
3) 장문의 텍스트에 대한 검색 품질이 떨어지거나, 지원하지 않는다.
이러한, 제약을 극복하고자 다음과 같은 M3 모델을 제안하였다.
M3는 100개의 언어를 지원하며, 각 언어에 대한 검색을 수행하는 것 (Multi-lingual Retrieval)뿐만 아니라
언어 간 교차 검색도 가능하다 (Cross-lingual Retriaval).
그리고 dense, sparse, multi-vector 3개의 다양한 검색 기능을 적용하였다.
또한 최대 8192 토큰까지 입력이 가능하다.
이러한 모델의 주요 학습 포인트는 3가지이다.
첫째, self-knowledge distillation이라는 방식을 통해
Dense, Sparse, multi-vector 3개의 검색 방식이 서로 상호 보완될수 있게 하였다.
이때, M3에서는 [CLS] 임베딩을 dense 검색용으로 활용하였으며,
그 외 임베딩은 sparse와 multi-vector용으로 활용하였다.
또한 self 지식증류를 적용하였다.
self 지식증류는 3개의 검색에 대한 점수를 통합하고 이를 teacher로서 활용하는 방식이다.
이는 앙상블 학습의 원리에 따라 (Bühlmann, 2012),
이러한 이질적인 예측기들이 더 강력한 예측기로 결합될 수 있다는 것에 기인하였다.
둘째, 배치 사이즈 최적화를 통해 자원과 학습에 대한 효율을 높였다.
배치 사이즈를 최적화하고자 문장 길이에 따라 group으로 묶고, 길이가 짧은 문장 batch는 더 많은 배치를 적용하였다.
셋째로, 광범위하고 질 좋은 데이터 수집/정리를 수행하였다.
1) 대량의 unsupervised data를 추출하였고,
2) supervised용 fine-tuning 데이터를 만들었으며,
3) GPT3.5를 통해 데이터를 증강하였다.
[3. M3 모델]
M3 임베딩 모델은 3가지 특징이 있다.
1) 긴 input token지원이 가능하고(Granularities)
2) 여러개의 언어를 지원할뿐만아니라, x언어로부터 y언어로의 교차언어 검색이 가능하다.
3) dense, sparse, multi-vector 3개의 검색을 지원한다.
[3.1 Data Curation]
Train Data(왼쪽)와 허깅페이스에서 확인가능한 파인튜닝 Data 목록(오른쪽)
데이터는 크게 3가지로 구성된다.
1) unlabeled corpora에서 추출한 unsupervised data
2) labeled corpora에서 수집한 supervised용 fine-tuning 데이터
3) 합성/증강을 통한 증강 데이터.
1. unsupervised data는 시맨틱 구조에 기반하여 추출되었는데,
title-body, title-abstract, intruction-output처럼 그 구조를 뜻에 맞게 정의하였다.
데이터는 wikipedia나, news 데이터 등을 활용하였으며, 교차 언어 검색을 위해 번역 데이터셋도 활용하였다.
2. fine-tuning data는 적지만 다양하고 높은 품질의 데이터를 모았다.
영어 기준으로 HotpotQA ~ SimCSE 등이 있다.(데이터 테이블 참조)
3. 합성 데이터는 길이가 긴 문서 데이터가 되게 하기 위해 wiki나 MC4 같은 곳에서 긴 기사들을 샘플링 하였다.
이때 질문은 GPT 3.5를 활용하여 생성하였다. (Appendix에 Prompt가 수록됨)
[3.2 Hybrid Retrieval]
Dense Retrieval.
query에 대한 임베딩 값을 [CLS]에 대한 임베딩 값으로 사용하였다.
이때, 노멀라이즈하고 사용하였다.
Passage(문서)도 마찬가지로 임베딩 값을 구하였다.
쿼리와 문서 간의 유사도는 내적으로 구하였다.
Lexical Retrieval.
인코더를 통과한 임베딩 값은 각 단어별 중요도를 추정하는데 활용되었는데,
이는 사전기반 검색을 용이하게 해준다.
단어별 중요도 즉, Term weight는 임베딩 * 가중치 행렬(W)에 Relu를 적용하여 도출하였다.
그리고 Query와 Passage 간의 유사도 점수는
Query와 Passage에서 겹치는 단어에 대한 term weight를 곱하는 방식으로 산정하였다.
Multi-Vector Retrieval.
Multi-Vector Retrieval의 경우, 전체 임베딩을 활용하였다.
가중치 행렬 (dxd)에 전체 임베딩 Hq(dxN)을 곱하여 norm을 취하였다.
( (dxd) * (dxN) = (dxN) )
여기서 N은 문장의 길이(토큰의 개수)를 의미한다
즉, Query/Passage의 토큰 개수가 n, m개이고, (dxN) 크기의 Eq와 (dxM)크기의 Ep가 있다면,
모든 Query 토큰에 대해 각 토큰 임베딩과 가장 유사한 Passage 토큰 임베딩과의 내적값을 구하고,
모두 합한 뒤 평균내었다. (비약이 있어보인다)
[3.3 Self-Knowledge Distillation]
self 지식증류는 3개의 검색에 대한 점수를 통합하고 이를 teacher로서 활용하는 방식이다.
앙상블 원리의 기반으로, 다른 검색 방법들로부터의 예측들이 통합될 수 있다고 봤다.
앙상블의 simple form으로 유사도 점수는 단순히 각 스코어의 합산으로 산정하였다.
다음과 같이 각 Retrieval에 대한 Loss Function을 수정하므로써,
total score인 S_inter가 teacher의 역할을 갖도록 했다.
p()함수는 softmax인데, infoNCE Loss에서 나타나는 식의 형태를 softmax라는 단어로 간략히 표현한 것이다.
(엄밀히 말해서, teacher의 역할로써 loss 펑션이 되려면,
teacher와 student 간의 차이를 loss로 두어야하는데, 이 식이 ditillation이 맞는지 잘 모르겠다)
M3 모델의 기본 뼈대는 XLM-Roberta를 활용하였다.
첫번째 Stage에는 dense retrieval만 사전학습하였고, 대량의 unsupervised 데이터로 basic contrastive learning하였다.
두번째 Stage는 사전학습된 임베딩 모델을 self-knowledge distillation 방식으로 3가지 검색 기능에 대해 모두 학습(파인튜닝)하였으며,
labeled/synthetic data를 활용하였다. 이때, ANCE라는 논문에서 제안한 문서에서 negative sample을 찾아주는 방법론을 활용하였다.기본 Loss Function 식 (InfoNCE Loss 형태)
[3.4 Efficient Batching]
메모리의 한계가 존재할때, Large batch를 위해 input data를 짧은 문장으로 변환한거나, 잘라내는 경우가 많았다.
(batch size가 클수록 학습이 더 잘되는 방법론 존재 : Simcse 등)
그러나, M3 임베딩은 짧은 문장부터 긴 문장까지 커버하는 것을 목표로하였기때문에 그렇게 할수 없었고,
효율적인 배치 트릭으로 Large batch가 가능하도록 해야했다.
이를 위해 문장 길이에 따라 훈련 데이터를 group화하고, mini-batch를 뽑을때 group 내에서만 샘플링하도록 하였다.
이를 통해 쓸데없이 버려지는 Padding token을 최소한하도록 하였다.
긴 문장의 group을 학습할때는 batch 사이즈를 더 작게 하였다(sub-batch)
즉, Table 9.처럼batch size를 문장에 길이에 따라 가변하였다.
[CLS]만으로 학습하는 MCLS 방식을 제안했으나, 뒤에서 결과를 봤을때는 성능이 좋지 않았다.
[4. Experiment]
우리는 M3 모델의 평가를 여러 언어 검색, 교차 언어 검색, 긴 내용의 문서 검색 3가지 파트로 나눠서 진행하였다.
[4.1 Multi-Lingual Retrieval]
18개 언어 쿼리/문서 데이터셋인 MIRACL로 평가하였으며, nDCG@10으로 평가하였다.
경쟁모델로는 BM25, mContriever, E5_mistral7b 등을 정하였다.
BM25와 M3간의 공정한 비교를 위해 토크나이저를 같게하였다. (XLM-Roterta의 vocab 활용)
또한 OpenAI 모델과도 비교하였다.
Table 2와 같이 M3는 E5_mistral7b보다도 더 적은 가중치로도 더 좋은 성능을 내었다.
영어를 포함한 전체 언어에 대한 평균 점수가 더 좋은 모습을 보였다.
특히, Sparse 검색 방식만으로도 BM25를 능가하는 모습을 보였다.
또한, 멀티 벡터 검색 방식이 높은 성능을 내는 것을 확인할수 있었다.
그리고, Dense+Sparse 방식만 섞어도 E5나 OpenAI 임베딩보다 더 좋은 성능을 내는 것이 확인되었다.
[4.2 Cross-Lingual Retrieval]
교차 언어 검색은 MKQA 벤치마크로 평가하였다.
각 언어에 대해 질문하고, 그 답변을 영어 문서에서 찾는 방식이었다.
Recall@100 방식으로 평가하였다.
실험 결과는 Multi-lingual과 동일하게, Cross-lingual에서도 M3가 가장 좋은 성능을 보였다.
다만, 그 성능의 차이가 더 적었으며 일부 언어에서는 E5가 더 좋은 경우도 많이 존재했다.
Sparse의 경우도, BM25보다는 성능이 좋았지만 DPR과 같은 다른 기존의 방법론보다는 높지 못했다.
(개인적으로,
multi lingual과 cross lingual에서 멀티벡터가 Dense, Sparse 보다 더 우위를 보이는것이 신기하다.
그러나, 저자는 이를 언급하지 않았고 Dense+Sparse 조합만 해본 것이 아쉽다.
멀티벡터+Sparse 조합은 잘 안나와서 언급을 안한 것인지...)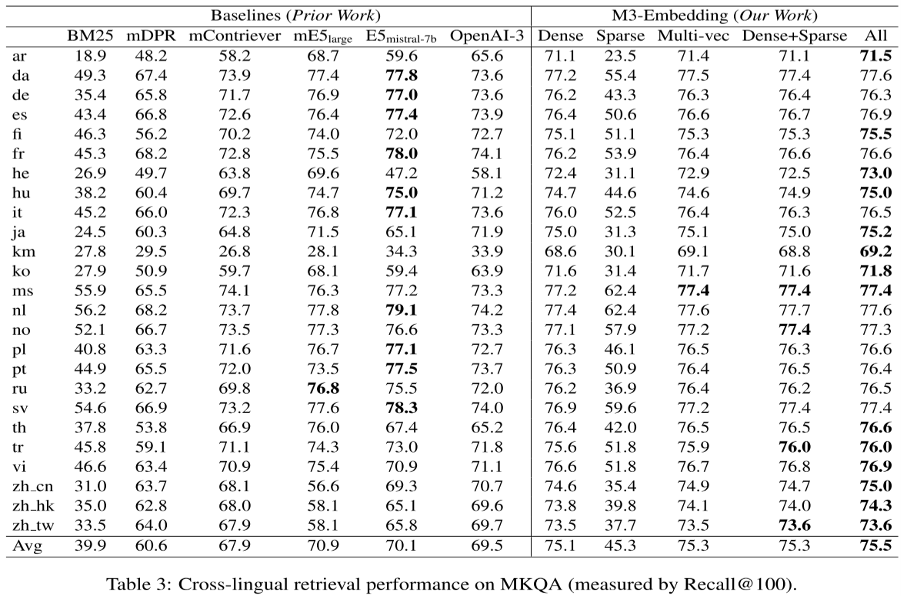
[4.3 Multilingual Long-Doc Retrieval]
MLDR, NarrativeQA 데이터셋으로 긴 문서 검색을 평가했다.
M3가 OpenAI나, E5보다도 성능이 훨씬 좋았다.
[4.4 Ablation syudy]
self-knowledge distillation을 제거하고서 학습했을때보다 self-knowledge distillation을 적용했을때,
각 검색 방식이 모두 성능이 더 높은 것을 확인할수 있었다.
self-knowledge distillation 제거는 각 검색방식만으로 loss function을 적용한 것으로 추정된다.
마찬가지로,
RetroMAE + Unsupervised + Fine-tuning으로 학습하는 것이 Ablation된 것보다 더 성능이 좋음을 확인하였다. 728x90
728x90'AI 논문 리뷰' 카테고리의 다른 글
