-
왜 대부분의 LLM은 Decoder-only 형태로 구현되는걸까자연어처리(NLP)와 인공지능(AI) 2024. 6. 5. 22:11
대부분의 LLM은 Decoder-only 방식으로 구현된다.
LLama, Palm, Mistral, GPT 시리즈 등 대부분의 모델이 그러하다.
(유일하게 Google의 Gemini 문서에서 Encoder-Decoder를 '언급'하고 있다.명확하게 Gemini가 Encoder-Decoder라고 표기한 적은 없다)
Encoder-Decoder 타입도 있는데, 왜 대부분의 LLM은 Decoder-only 형태로 구성되는걸까?
그 이유는 약 5가지 정도 볼수 있다.1. simple하게 구현가능한 autoregressive learning과 semi-supervised learning만으로도
강력한 zero-shot 성능을 발휘할 수 있기 때문이다.
What Language Model Architecture and Pretraining Objective Work Best for
Zero-Shot Generalization? 라는 논문에서는
Decoder-only 방식(Casual / Non-Casual)이 Encoder-decoder 방식보다 더 높은 Zeroshot 성능을 발휘한다고 밝혔다.또한, 대량의 Corpus에 대해 autoregressive하게 semi-supervised learning을 쉽게 구현할 수 있다.
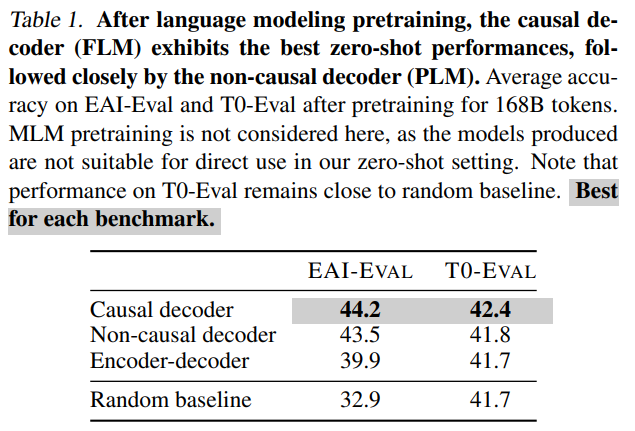
출처 : What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization? 2. In-Context Learning(이하 ICL)은 가중치 변화와 유사 효과 가져올 수 있다는 연구 결과가 존재한다.
다시 말해, few-shot 예제 등의 Prompt를 통해 가중치 학습의 효과를 가져올수 있다는 것이다.
Why Can GPT Learn In-Context?
Language Models Implicitly Perform Gradient Descent as Meta-Optimizers 라는 논문에서는아래 공식과 같이 ICL이 가중치 변화와 유사하게 작용할수 있음을 수학적으로 표현하였다.
이는 다시말해 Encoder를 추가하여, 굳이 Prompt에 대한 translation 손실을 가져갈 필요가 없는 셈이다.
출처 : Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers 3. Emergent Ability(창발성) : Emergent Ability란, 모델 사이즈가 특정 수준을 넘어서게 되면,
학습 능력이 크게 상승하는 것을 말한다.(아래 그림 참고)
현재까지 이는 decoder-only에서만 확인된다.(encoder-decoder에 창발효과가 없다는 것은 아님. 그냥 실험 사례가 없음 - 못 찾은 것일수도...)
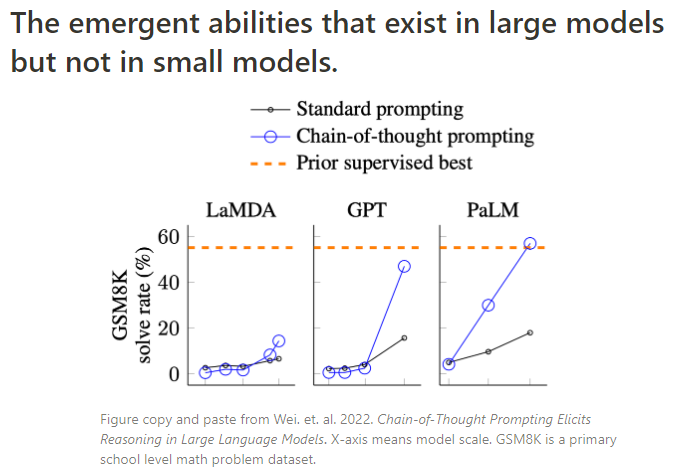
출처 : A Closer Look at Large Language Models Emergent Abilities 4. autoregressive learning을 할 경우, 이전의 출력을 다음의 입력으로 재활용하므로
Key, Value를 재사용하는 이점이 생긴다. 이는 속도와 계산에 대해 큰 이점을 가져다준다.
5. Masked Attention을 통한 Full-rank 효과
Decoder-only 아키텍처에서는 masking으로 인해 attention matrix가 하삼각 형태(아래 그림의 Casual)로 제한되게 된다.
이는 이론적으로 full-rank 상태를 유지하게 하고, 더 강한 표현 능력을 갖는 가능성을 갖게 된다.
출처 : Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer 참고 자료 및 출처 :
https://medium.com/@yumo-bai/why-are-most-llms-decoder-only-590c903e4789
728x90'자연어처리(NLP)와 인공지능(AI)' 카테고리의 다른 글
Last_hidden_state와 Logit (5) 2024.09.24 Batch Size, Iteration, Step, Epoch 이해하기 (4) 2024.09.22 문장 기반 임베딩 모델의 Semi-supervised 학습 방법 (0) 2024.05.23 음성인식에서 쓰이는 FFT(Fast Fourier Transform)와 STFT(Short Time Fourier Transform) 그리고 Spectrogram의 개념과 차이점 (0) 2024.05.23 Retrieval-Augmented Generation(RAG)의 흐름과 아키텍쳐 (1) 2024.05.21