-
임베딩 모델 평가) MTEB 코드 살펴보기 (1)자연어처리(NLP)와 인공지능(AI) 2025. 2. 25. 00:00
아래 설명처럼 평가된 한국어 임베딩 모델 순위 확인하기 : https://github.com/OnAnd0n/ko-embedding-leaderboard
다음 글 : 임베딩 모델 평가) MTEB 코드 살펴보기 (2) - Custom Model 평가
MTEB(Massive Text Embedding Benchmark)은 텍스트 임베딩 모델을 다양한 자연어 처리(NLP) 태스크에서 평가하기 위한 벤치마크이다. 문장과 문서 임베딩 모델의 성능을 비교할 수 있도록 리더보드가 존재하며, 검색, 클러스터링, 분류, 의미적 유사도 등 여러 태스크로 나뉘어 모델의 임베딩 성능을 평가한다.
현재 MTEB는 2.0버젼으로 리더보드를 새롭게 꾸민 상태이고, MTEB kor(한국어) 버젼도 존재한다.
(아래 그림처럼 2.0 버젼의 한국어 리더보드에 아직 공식 한국어 지원 모델이 많이 보이지 않는다. 조금 어수선한 상태다)

임베딩의 성능을 측정하는 몇 개의 Task를 살펴보면 다음과 같다.
1. STS (Semantic Textual Similarity)
- 가까운 문장을 벡터로써 얼마나 가깝게 표현했는지를 측정할수 있다.
2. NLI (Natural language Processing) / Pair-Classification
- 두 문장 간의 관계가 모순, 함의, (+중립) 관계인지를 잘 맞출수 있는지를 보고자 한다.
3. Information Retrieval
- 변환된 벡터를 통해 검색 성능이 얼마나 잘 나오는지 확인한다.
4. Clustering
- 변환된 벡터가 클러스터링 성능이 얼마나 잘 나오는지 확인한다.
MTEB에는 그 외에도 Classification, Reranking, Summarization 등 많은 Task가 존재하며, 가장 유명한 벤치마크다.
이제, 학습만큼이나 중요한 임베딩 평가 수행을 위해, MTEB를 톺아보자.
아래 MTEB의 기본 Example 코드를 보자.
MTEB의 기본 코드에서도 알수 있듯이, (내 기준으로) 크게 3개 구역으로 나눌수 있다.
1. Model
2. Task
3. Evaluation
여기서 Task는 다시 Task와 AbsTask로 나뉜다.
1. Model
get_model은 말 그대로 Model을 불러오는 영역이다.
MTEB에서 평가를 지원하는 모델의 종류는 굉장히 다양하기에, 코드가 복잡해보이지만
우선, Sentence-Transformer의 모델을 기준으로만 Model이 호출되는 순서를 확인해보자.
model = mteb.get_model(model_name)
def get_model in /mteb/models/overview.py (디렉터리를 의미함)
ㄴ def get_model_meta
ㄴ def model_meta_from_hf_hub
ㄴ class ModelMeta in /mteb/model_meta.py
=> 이때, class ModelMeta는 아래 그림처럼 load_model 메소드를 갖는다.
load_model에서 loader 인자가 있다면, 바로 sentence_trasfomers_loader로 모델 호출을 실행한다.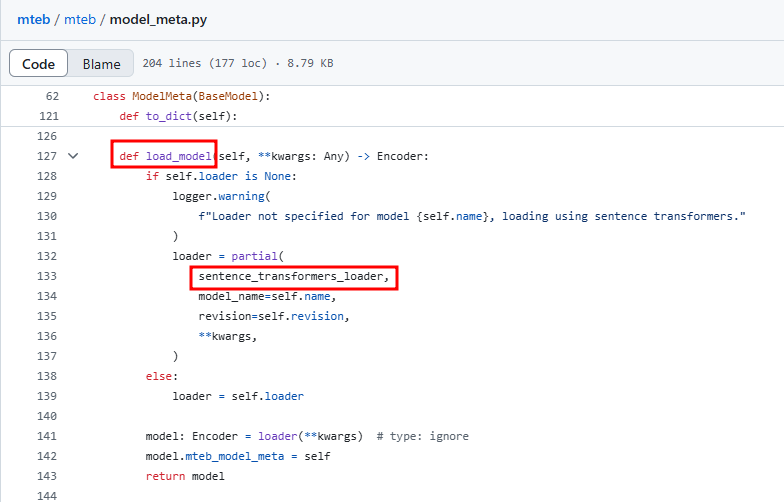
앞서 얘기한 def sentence_trasfomers_loader는 다시 다음과 같은 구조로 호출이 이어진다.
ㄴ class SentenceTransformerWrapper in mteb/models/sentence_transformer_wrapper.py
ㄴ 해당 class에서 self.model = SentenceTransformer(model, ~~)로 선언됨.
즉, 정리해보면, 아래 코드는 SentenceTransformer로 그냥 모델 불러오는 코드이다.model = mteb.get_model(model_name)
만일, SentenceTransformer가 아닌 transformer (AutoModel.from_pretrained(model_name))등으로 불러졌다면,
MTEB에서 친절하게 mteb/encoder_interface.py를 설정해두었으니, 이에 따라 Encoder를 wrap해주면 된다.
아래 그림은 self.loader가 없을 경우에 Encoder를 땡겨오는 오는 모습이다.
(자세한 설명이 궁금하다면? 임베딩 모델 평가) MTEB 코드 살펴보기 (2) - Custom Model 평가)
2. Task
tasks = mteb.get_tasks(tasks=["Banking77Classification"])
get_tasks는 평가 TASK에 맞게 평가 데이터셋을 불러오는 코드이다.
위의 예시처럼, 평가 데이터셋을 직접 선언할수도 있고, TASK_TYPE = 'Clustering'처럼 TASK 타입자체를 선언할수도 있다. 그렇게 되면 MTEB에서 Mapping해둔 Clustering 관련 평가 데이터셋이 load된다.
get_tasks의 호출구조를 확인해보자.
def get_tasks in /mteb/overview.py
ㄴ 1) tasks 인자가 input으로 존재할때,
=> class MTEBTasks(_tasks) 실행. // 여기서 _tasks는 list 형태인 task의 집합이다.
ㄴ 2) tasks 인자가 input으로 없을때, languages, task_type 등의 input 정보로 _tasks를 선언함.
=> class MTEBTasks(_tasks) 실행
결론적으로 해당 코드는 task의 list를 만들어내는 것이다.
task의 의미가 여기저기 혼용되는데, 지금 설명에서는 평가 데이터셋의 list라고 생각하면 된다.
(ex. [kor_STS, klue_STS, ..., ])
3. Evaluation
evaluation = mteb.MTEB(tasks=tasks) results = evaluation.run(model, output_folder=f"results/{model_name}")
다음은 Evaluation 영역이다.
mteb.MTEB는 즉, 해당 class MTEB는 /mteb/evaluation/MTEB.py에 존재한다.
이전에 선언된 task의 list를 인자로 넣어
평가를 위한 MTEB 객체를 생성하고,
해당 객체에 run 메소드를 실행하면 된다.
아래 그림은 class MTEB 내에 있는 run 함수이다.
Model, Task처럼 호출을 일일이 따라가서 설명하기 어려운 구조라
큰 그림으로 먼저 설명하는 것이 좋겠다.
evaluation은 크게 보면 아래 순서처럼 수행된다. (STS 평가를 예로 듬)
Task(Task_list) → AbsTask → ex) AbsTaskSTS.py → class STSevaluator in /mteb/evaluation/evaluators/STSEvaluator.py
Task_list(평가 데이터셋 list)가 선언되었다면, AbsTask 코드로 진입한다. AbsTask에서는 수행되어야할 평가 데이터셋이 어떤 작업인지(STS인지, Clustering인지)에 따라 그에 맞는 evaluator를 호출한다.
위 예시를 기준으루 수행 Task는 STS였으므로,
AbsTask에서 class STSevaluator를 호출하게 된다.

AbsTask 디렉터리 (평가 Task 별로 코드 파일이 나뉘어진 모습)

evaluators 내 실제 평가 class들이 확인된다.
그렇다면, class STSEvaluator는 어떻게 평가를 수행할까?
아래처럼 model (앞선 1. Model 영역에서 확인했듯이 Encoder) 을 인자로 받아
encode를 수행하여, 벡터화하고 cosine_similarity를 구한다. 아주 심플하다.
이런 식으로 접근하면, 평가 코드를 조금 더 유연하게 작성할 수 있다.
다음에는 Customizing하여 평가를 수행하는 방법(코드)와
각 Task 별로 어떻게 임베딩의 성능을 측정하는 방식에 대해 확인해보자.728x90'자연어처리(NLP)와 인공지능(AI)' 카테고리의 다른 글
임베딩 모델 평가) MTEB 코드 살펴보기 (2) - Customizing (1) 2025.02.25 FP32, TF32, FP16, BF16, Mixed Precision에 대한 이해 (5) 2024.10.03 Last_hidden_state와 Logit (5) 2024.09.24 Batch Size, Iteration, Step, Epoch 이해하기 (4) 2024.09.22 왜 대부분의 LLM은 Decoder-only 형태로 구현되는걸까 (2) 2024.06.05