-
Retrieval-Augmented Generation(RAG)의 흐름과 아키텍쳐자연어처리(NLP)와 인공지능(AI) 2024. 5. 21. 00:01
RAG란?
RAG란, LLM이 검색된 결과에 근거하여 답변하는 방식.
RAG의 뿌리는 페이스북(현 메타) AI 리서치 논문 (https://arxiv.org/pdf/2005.11401.pdf)이라고 볼수 있다.
- LLM은 환각(Hallucination)의 한계를 가짐. 또한 공개되지 않은 특정 도메인 분야 지식에 대한 작업에서 효과가 떨어짐. 또한 학습 시점 이후 데이터에 대한 정보가 없음
- 반면 RAG는 최신 데이터에 액세스할 수 있으므로 정보의 최신성을 갖추고, 분야별 애플리케이션에서 우수한 성능을 낼 수 있음
- 또한. 환각 효과를 보정/보완할 수 있음
[기본적인 RAG 수행 흐름] (아래 그림 참조)
- 문서 임베딩을 통한 벡터 DB 생성/저장
- 쿼리에 대한 벡터화 (이때도, 임베딩 활용)
- 쿼리 벡터와 관련이 높은 상위 N개의 항목을 벡터 DB에서 추출하여, LLM에 쿼리와 함께 제공
- LLM의 응답.

RAG의 기본적인 수행 흐름 [검색 방식에 대한 참고 자료]
-일반적인 Ensemble Retrieval의 흐름
검색에는 크게 3가지 방법론이 있다.
- 키워드 빈도 검색
- Dense 벡터 검색
- Graph 기반 검색
- 키워드의 빈도를 활용하는 대표적인 방법이, 바로 잘 알려져 있는 TF-IDF이다.
빈도를 활용한 검색 방법론 중 SOTA는 BM25이다.
그러나 빈도 키워드 검색은 유의어와 동의어를 포함하여 검색할수 없다는 태생적인 한계가 있다..
- Dense 벡터 기준으로 SOTA는 LLM 기반 임베딩 모델이다.
학습에 의존하므로, 신규 키워드에 대해 성능이 떨어지는 단점이 있다. (그러나, 이를 대량의 데이터로 커버)
- Graph 자체는 오래 사용되어왔지만, 검색에 적용하는 것은 신생에 가깝다.
어떤 Grapg DB 형태가 좋은지 그 실용성을 체크해봐야한다.
현재로서는 1번과 2번을 결합하여 활용하는게 일반적이다.(상호 간의 단점을 커버).
Ensemble Retrieval의 흐름 (출처 : medium, https://cdn-images-1.medium.com/v2/resize:fit:800/1*u4wm-Jn1ZnGhSxxhBLx_CA.png) - Semantic Search 시 활용되는, 임베딩 벡터 만드는 과정
임베딩 벡터 만드는 과정 (출처 : pdf로 저장해놨으나, 찾을수 없음) - 또다른 RAG의 기본/Advanced 아키텍쳐 + 7가지의 Failure point
Advanced RAG 아키텍쳐 (출처 : https://cobusgreyling.medium.com/seven-rag-engineering-failure-points-02ead9cc2532) [ RAG의 3가지 주요 패러다임 ]
RAG을 3가지의 패러다임으로 구분하고, 그 발전 방식을 확인해보자
< 기본 RAG >
기본 RAG는 RAG 연구의 초기 방법론을 지칭. 전통적인 인덱싱, 검색 및 생성 과정을 포함
낮은 검색 정확도, 응답 생성의 낮은 품질, 증강 과정의 어려움 등에 따라 발생하는 불필요한 반복, 부정확한 정보, 잘못된 문맥의 통합 등이 발생 가능
기본 RAG의 주요 구성요소로는 인덱싱(Indexing), 검색(Retrieve), 생성(Generation)
1. 인덱싱
1-1. 데이터 인덱싱- 데이터 정제, 데이터 검색/처리를 효율적으로 하기위한 기초 처리- 또는 문서를 구조화하는 방법- 랭체인 기준: Document loaders
1-2. 청크 분할- 실제 문서를 더 작은 단위(Chunk)단위로 쪼갬. 언어 모델이 처리할수 있는 맥락의 양을 고려하는 행위.- 랭체인 기준: Text Splitters
1-3. 임베딩 및 인덱스 생성- 청크 단위의 텍스트를 벡터로 인코딩. 임베딩 모델은 정확도는 물론 높은 추론속도 요구됨.- 텍스트 청크와 임베딩 값을 키-값 쌍 형태로 저장- 랭체인 기준 : Text embedding models, Vector stores
2. 검색- 랭체인 기준 : Retriver
2-1. 쿼리에 대한 벡터 변환- 랭체인 기준 : Retriever > MultiQueryRetriever, Self Query 등
2-2. 유사성 계산 (ex. cos, 내적, mmr)- 랭체인 기준 : Retriever용 함수 내 파라미터로써 구현
2-3. 필터- top k, Similarity score threshold 등- 랭체인 기준 : Retriever용 함수 내 파라미터로써 구현- retriever = db.as_retriever(search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5})
3. 생성
3-1. 주어진 질문과 관련 문서를 결합하여 새로운 프롬프트를 생성- 랭체인 기준(프롬프트) : prompt > PromptTemplate, ChatMessagePromptTemplate 등- 랭체인 기준(문서와 결합) : Chains > RetrievalQAWithSourcesChain, RetrievalQA 등
3-2. 프롬프트(+문서)에 기반한 답변 생성- 랭체인 기준(문서와 결합) : Chains > RetrievalQAWithSourcesChain, RetrievalQA 등< Advanced RAG >
고급(Advanced) RAG는 기본 RAG의 부족한 점을 개선하기 위해 개발된 패러다임.
이는 주로 검색 및 생성의 질을 향상시키기 위한 사전 및 사후 검색 방법을 포함.
고급 RAG는 크게 검색 전 절차(Pre-Retrieval Process), 검색 후 절차(Post-Retrieval Process), RAG 파이프라인 최적화(RAG Pipeline Optimization)의 3단계로 나누어볼 수 있음
====== ============ ===== ====== ============ =====
< 검색 전 절차(Pre-Retrieval Process) >
1. 데이터 인덱싱 최적화(Optimizing Data Indexing)
1.1 데이터 세분화 강화(Enhancing Data Granularity)- 불필요한 정보와 특수 문자를 제거하여 검색기의 효율성을 높이고- 엔티티와 용어의 모호성을 제거하며- 중복되거나 불필요한 정보를 최소화
1.2 인덱스 구조 최적화(Optimizing Index Structures)- 청크(chunk) 크기를 조정 (랭체인 기준 : RecursiveCharacterTextSplitter, ParentDocumentRetriever 등)- Fixed Size Chunking- Content-Aware chunking : 문단/문장 단위로 잘라내기- Recursive chunking- Overlapping 테크닉- Parent Child chunking- Chunk summarization : Content-Aware chunking로 문단 추출후, N자 이하로 요약하여 요약된 문장을 임베딩- Extract Candidate Question : 해당 문서에 해당하는 질문 N개를 추출하여, 이를 임베딩 적용- 인덱스 경로의 변경 (랭체인 기준 : ParentDocumentRetriever)- 그래프 구조의 정보를 도입 (랭체인 기준 : LangGraph)
1.3 메타데이터 정보 추가(Adding Metadata Information)- 각 데이터 청크(data chunk)에 날짜, 목적 등과 같은 메타데이터를 포함- 검색 효율성을 개선.
1.4 정렬 최적화(Alignment Optimization)- 문서 간의 차이점 또는 정렬을 위한 전략- 각 문서에 적합한 가상의 질문을 만들고, 그 질문을 문서와 함께 임베딩하여 보관- 추후 검색시, 이를 활용
1.5 혼합 검색(Mixed Retrieval)- 키워드 기반 검색, 의미 검색, 벡터 검색과 같은 다양한 검색 기술을 지능적으로 결합
2. 임베딩(Embedding)
2.1 정밀 조정 임베딩(Fine-tuning Embedding)- 도메인 특화, 전문 분야 용어에 맞게 임베딩 모델 학습/튜닝- 본 서베이 논문에서는 BGE(BAAI 2023)를 고성능의 튜닝 가능한 모델로 소개
2.2 동적 임베딩(Dynamic Embedding)- 정적 임베딩을 각 단어에 대해 하나의 벡터만을 사용하는 것으로 정의- 동적 임베딩은 주변 단어에 따라 단어의 임베딩이 달라질 수 있게함.- ex. sentence transformer embedding< 검색 후 절차(Post-Retrieval Process) >
- 검색 후 절차는 고급 RAG에서 매우 중요한 단계- DB에서 검색된 중요한 문맥을 질의와 결합하여 LLM에 입력하는 과정- 검색 결과로 나온 모든 문서를 한번에 LLM에 제공하는 것은 비효율적, LLM의 context window 크기를 초과할수 있음.1. 순위 다시 매기기(ReRank)- 검색된 결과들에 대해 쿼리와의 관련성을 다시 평가하여 Rank를 다시매김.- cohereAI rerank, bge-rerank, LongLLMLingua 등의 여러 방식 존재.@ CoherAI Rerank 설명 (https://txt.cohere.com/rerank/)"companies can retain an existing keyword-based (also called “lexical”) or semantic search system for the first-stage retrieval and integrate the Rerank endpoint in the second stage re-ranking"
=> ReRank를 통해서 기존의 키워드 기반의 검색 결과와 벡터 기반의 시멘틱 검색 결과를 통합할수 있다.
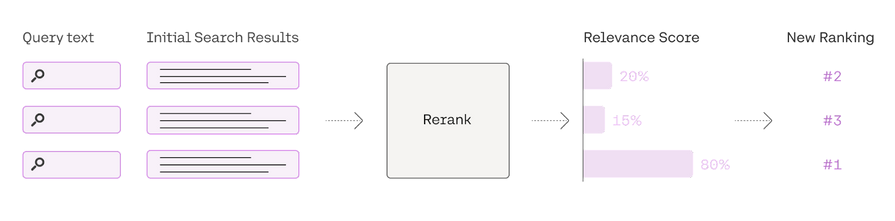
Rerank 흐름 2. 프롬프트 압축(Prompt Compression)
- 전체 콘텍스트 길이를 줄이는 데 중점(중요하지 않은 맥락은 압축, 중요한 문단은 강조)- Because 검색된 문서에서 발생하는 잡음(noise)이 RAG 성능에 부정적인 영향을 끼칠수 있으므로- Train된 압축기로 context 압축 (Recomp [Xu et al., 2023a]), 광범위한 Context를 다룸(Long Context[Xu et al., 2023b]), LLM의 주요 정보 인식을 향상시키기 위해 계층적 요약 트리를 설계([Chen et al., 2023a])< RAG 파이프라인 최적화 (RAG Pipeline Optimization) >
- '검색의 효율성' vs. '검색에서의 맥락적 정보의 풍부함' 사이의 균형을 달성하는 것이 목표
1. 하이브리드 검색(Hybrid Search)- 키워드 기반 검색, 의미론적 검색, 벡터 검색과 같은 다양한 기술을 혼합
2. 재귀적 검색 및 쿼리 엔진(Recursive Retrieval and Query Engine)- 작은 Chunk로 매칭하고 부모(상위 크기 문서)의 문서를 리턴(Small2Big, Parent&Child의 개념, 랭체인 기준 : ParentDocumentRetriever)
3. 역추적 프롬프트(StepBack-prompt)- LLM이 특정 사례에 치우쳐 생각하는 것이 아니라, 일반적인 개념이나 원리에 대해 추론하도록 장려하기 위한 방법- 대규모 언어 모델(LLM)을 사용하여 고수준의 개념과 원리를 추출하고, 이 정보를 검색 과정에 활용- 도전적인 추론 집약적 작업에서 눈에 띄는 성능 향상을 보였음([Zheng et al., 2023])4. 서브쿼리(Subqueries)- 다양한 질의 전략을 통해 효율적인 검색을 도모, 복잡한 쿼리를 여러 개의 쿼리로 분리하는 것이 기초 개념- 가장 기본적인 순차적 청크 쿼리 외 트리 쿼리, 벡터 쿼리 등- "Sub-queries: LLMs tend to work better when they break down complex queries. You can build this into your RAG system such that a query is decomposed into multiple questions." (https://towardsdatascience.com/10-ways-to-improve-the-performance-of-retrieval-augmented-generation-systems-5fa2cee7cd5c)
5. HyDE(Hypothetical Document Embeddings)- LLM이 생성한 문장이 사용자의 질의보다 임베딩 공간에서 더 가까울 수 있다는 가정에 기반- LLM을 사용하여 가상의 문서(= LLM의 답변)를 생성하고, 이를 임베딩한 후,이 임베딩을 사용하여 실제 문서를 검색하는 방법.- 질의와 문서 간의 유사성이 아닌, 답변과 문서 간의 유사성에 초점< RAG 평가 (RAG Evaluation) >
평가는 크게 2가지 종류로 나뉘는데,
하나는 검색기나 생성기 등의 각각의 모듈들에 대한 독립적인 평가(independent evaluation)- 검색 모듈(Retrieval Module) : 적중률(Hit Rate), MRR, NDCG, 정확도(Precision)- 생성 모듈(Generation Module) : 문맥의 관련성(relevance) 또는 사용자 질의와 검색된 문서들간의 연관성
입력으로부터 출력까지의 전체 과정을 평가하는 엔드-투-엔드 평가(end-to-end evaluation; 종단간 평가)가 있음.
- 레이블이 없는 콘텐츠(Unlabeled Content)에 대한 평가 : 답변 충실도(Answer Fidelity), 답변 관련성(Answer Relevance), 무해성(Harmlessness) 등- 레이블이 있는 콘텐츠(Labeled Content)에 대한 평가 : 정확도(Accuracy) 및 EM(Exact Match) 등- 기타 : 수행하는 작업에 따라서 별도의 지표를 사용 (ex. 질문-답변 Task)[그림. 평가 프레임워크(Evaluation Frameworks)]
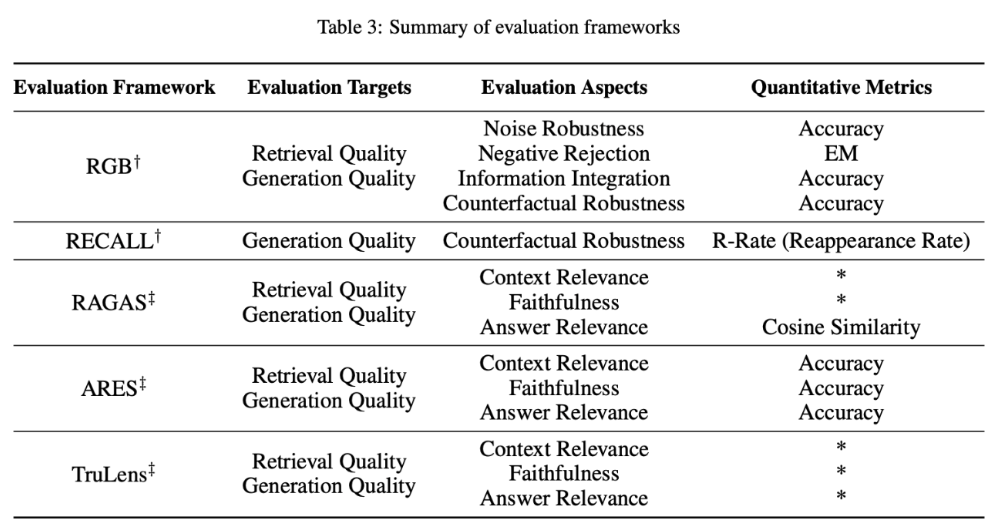
참고 자료 :
https://arxiv.org/pdf/2312.10997v1.pdf
https://python.langchain.com/docs/modules/data_connection/retrievers/
728x90'자연어처리(NLP)와 인공지능(AI)' 카테고리의 다른 글
Batch Size, Iteration, Step, Epoch 이해하기 (4) 2024.09.22 왜 대부분의 LLM은 Decoder-only 형태로 구현되는걸까 (2) 2024.06.05 문장 기반 임베딩 모델의 Semi-supervised 학습 방법 (0) 2024.05.23 음성인식에서 쓰이는 FFT(Fast Fourier Transform)와 STFT(Short Time Fourier Transform) 그리고 Spectrogram의 개념과 차이점 (0) 2024.05.23 RAG와 LLM 그리고 임베딩(Embedding) 모델의 동향 (1) 2024.05.20
