-
논문 리뷰) SimCSE_Simple Contrastive Learning of Sentence EmbeddingsAI 논문 리뷰 2024. 5. 21. 20:58
본 글은 [Open-Up] 오픈소스 소프트웨어 통합지원센터로부터 지원받아 작성하였습니다.
[요약]
21년에 발표된 SimCSE는 Contrastive learning을 통한 학습 방법론을 제안했는데, drop-out을 활용하여 하나의 문장을 Positive Pair(유사 문장)로 구성한 것, 그리고 학습 단위인 Batch 내에서 다른 문장은 Negative로 취급한 것이 핵심 아이디어다.
drop-out은 일반화된 모델의 성능을 위해 랜덤하게 일부 뉴런을 비활성화시키는 방식인데, 같은 문장이 입력되더라도 출력되는 임베딩 값이 달라질 수 있게 된다. SimCSE는 이 부분을 활용하여, 동일 문장을 2번 Encoder에 입력함으로써 마치 유사한 문장 2개가 입력되는 것처럼 활용하였다.
[핵심 아이디어]
- Contrastive learning을 수행할 때 하나의 문장을 Positive Pair로 구성하고,Batch 내 다른 문장은 Negative로 취급(가정). Unsupervised, Supervised setting을 모두 제안.
- Unsupervised SimCSE : pred-trained encoder에 input 문장을 2회 통과시킨다.
이때, 다른 dropout을 통과하여 2개의 임베딩 z, z′을 얻고 positive pair로 활용.
이를 통해 dropout을 노이즈로 사용해 data augmentation 효과를 얻음.Dropout 만으로 기존 연구들 성능을 뛰어넘음.
- Supervised SimCSE : NLI dataset을 활용,NLI에서 제공하는 entaiment 문장과 contradiction 문장을 학습함으로써 성능을 더 높였음.
- MultipleNegativesRankingLoss를 구현하여 SimCSE로의 훈련을 간단하게 할수 있음
[1. Introduction]

SimCSE 학습 방식
입력 문장을 똑같이 2개 넣어서, contrastive learning을 수행하였다.
이때, drop out이 noise의 역할을 수행할수 있다고 보았다.
그리고 이러한 dropout이 data-augmention을 이루고, representation collaspse를 완화시킨다는 사실을 발견하였다.
Unsupervised SimCSE는 다음과 같이 학습하였다.
똑같은 문장을 인코더에 입력하여, drop-out을 통해 다른 임베딩이 나올수 있도록 했다. 마치 'positive-pair'처럼.
그리고, 그외에 batch 내에 있는 다른 문장들은 'negative'로 가정하여, negative 문장들 속에 positive 문장 간의 거리가 가까워지도록 하였다.
Supervised SimCSE는 NLI dataset으로 학습하였다.
여러 데이터셋으로 실험해본 결과, NLI dataset에서 entailment, contradiction pair를 활용한 것이 특히 임베딩 성능 향상에 효과적이었다
STS dataset으로 모델 평가를 수행하였다.[3. Unsupervised SimCSE]
Table 1.을 보면, Dropout을 활용한 data-augmentation이 제일 성능이 좋았다.
loss 펑션은 다음 식과 같다.
분자(positive-pair)는 drop-out을 통과한 same-sentence 간의 유사도.
분모(negative-pair)는 batch 내에 모든 sentence들 간의 유사도이다.
여기서 drop-out은 우리가 따로 추가할 필요없이 Transoformer에 있는 dropout을 활용했다.
dropout 비율은 우측 표와 같이 p = 0.1이 제일 좋았다.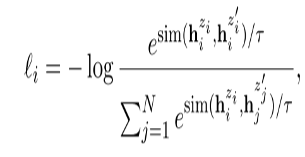

Unsupervised Loss Function과 Dropout 비율 
Table1
[4. Supervised SimCSE]
아래 데이터셋 중에서 어떤 labeled dataset이 positive-pairs를 구축하기에 적합한 지 알아보았다.
- QQP, Flickr30k, ParaNMT, SNLI / MNLI
SNLI, MNLI의 entailment pair를 활용하는게 제일 성능이 좋았다.
여기서 우리는
NLI 데이터셋에 모순 pair 문장이 존재한다는 이점을 활용하였다.
이는 hard negative로서의 역할을 가능하게 할 것이라고 봤다.
Table 4에서처럼, 실제로 hard negative를 넣어주었을때, 성능이 향상되었으며, 이를 우리의 최종 모델로 확정지었다.
negative가 포함된 loss는 우측과 같다(그러나, Unsupervised와 크게 다르지 않음. batch 내 다른 문장은 모두 negative 처리)

Table 4.와 Supervised Loss function
[6.3 Ablation Study]
Unsupervised의 경우는 MLP 계층을 train할때만 추가하고, test할때는 제거하는 것이 제일 좋았고,
Supervised의 경우는 MLP 계층을 train/test 할때 모두 가지고 있는 것이 좋았다.
그리고, 우리 모델을 그렇게 구성하였다.
(여기서 MLP는 Pooling Layer를 얘기하는 듯?)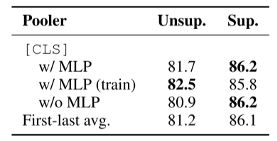
Ablation Study
[A. Training Details.]
SimCSE는 learning rate를 적절하게 튜닝해주기만 한다면 배치 사이즈에 크게 민감하지 않은 양상을 띠었다.
이는 Contrastive learning은 큰 batch size를 요구한다는 주장과는 모순되는 내용이다.
(A simple framework for contrastive learning of visual representations 논문)
아마도, 이것은 pretrained checkpoint에서 시작했기에, 이미 좋은 초기값에서 출발이 가능했기때문일수도 있다.728x90'AI 논문 리뷰' 카테고리의 다른 글