-
논문 리뷰) Multilingual E5 Text Embeddings (mE5)AI 논문 리뷰 2024. 6. 6. 11:33
본 글은 [Open-Up] 오픈소스 소프트웨어 통합지원센터로부터 지원받아 작성하였습니다.
[통합 요약]
Multilingual E5 Text Embeddings: A Technical Report는 이름 그대로 논문이 아니라 기술 Report이다.그래서인지 내용도 굉장히 짧다.
하지만 E5 → E5 mistral 7B → Multilingual E5(이하 mE5)로 이어지는 꾸준한 모델의 발전과 파생 그리고 여러가지 시도를 확인할 수 있다. 그리고 mE5는 생각보다 잘 쓰이는 모델이기도 하다.
mE5 모델은 E5 mistral 7B 모델에서 쓰인 2-stage 학습 방법론과 생성 데이터를 BERT 계열의 모델에 적용한 것이다.
(E5 mistral 7B는 지난 번 리뷰하였으므로, 설명은 생략하겠다. E5 mistral 7B 글)
- Base 모델 : xlm-roberta-large, xlm-roberta-base, xlm-roberta-small
- Best 모델 : multilingual-e5-large-instruct (해당 모델로 24년 6월 기준 MTEB 리더보드 20위)
- 특징 : BERT 계열로 임베딩 모델을 구현, 적은 메모리 사용량(2.1GB)과 적은 임베딩 차원수(1024)로 높은 품질의 임베딩을 생성. Max input token은 514로 Not Bad.
MTEB 리더보드
[Training]
논문 "Improving Text Embeddings with Large Language Model"에서 제안한 학습 방법론은 2 stage로 구성된다.
첫 번째 단계는 weakly-supervised의 contrastive learning이고, 두 번째 단계는 소량의 고품질 labeled 데이터를 통한 fine-tuning이다.
첫 번째 단계에서, 모델은 약 10억 개의 text-pair를 가지고 weakly-supervised contrastive learning을 수행한다. 이를 통해 모델은 대규모 데이터셋에서 다양한 언어적 패턴과 의미를 학습한다. 이때, batch 사이즈는 32k로 총 3만 step 동안 훈련을 진행한다(배치 사이즈가 어마무시하다). 훈련 과정에서는 InfoNCE loss를 사용하며, In-Batch Negative만을 활용한다.
(InfoNCE Loss와 In-Batch Negative는 지난 번 E5 mistral 7B에서 설명하였으므로 생략하겠다. E5 mistral 7B 글)
이 단계에서 적용된 기타 hyper parameter는 기존의 english-E5 모델과 똑같이 설정하였다.
두 번째 단계는 소량의 고품질 labeled 데이터를 통한 fine-tuning이다. 이 단계는 모델이 보다 정확하고 정교한 임베딩을 생성하는 것을 목적으로 한다. 또한 mined hard negatives and knowledge distillation을 활용했다.
mined hard negatives과 knowledge distillation은 기존의 english-E5 모델 논문에서 제안된 방법이다.
여기서 mined hard negatives란, 유사도는 높게 나왔지만 실제로는 negative인 문단(Passage)을 말한다.
예를 들어, 'What is Python?' 질문(Query)에 대해, 'Java is a class-based programming language'라는 문단(Passage)이 그럴 것이다. 이러한 mined hard negatives를 학습하여 모델이 유사도 판정하기 어려울만한 문장들을 더 잘 분별할 수 있도록 한다. 이때 mining하는 도구와 방식은 BM25나 다른 Retrieval 모델들이 주로 사용된다.예를 들어, 어떤 Query에 대해 정답인 Passage를 제외시킨 문서집단이 있다고 하자.
그 문서 집단에서 BM25와 Retriever를 통해 높은 유사도를 가진 문서를 찾아내면, 이는 Hard Negative Passage로 간주할수 있다.

SIMLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval에서 설명하는 mined hard negatives
knowledge distillation은 더 성능 좋은 모델을 teacher로 활용하는 방식이다.
예를 들어 CrossEncoder 모델을 teacher 모델로 두고 내가 학습시키고 싶은 모델이 teacher 모델과 얼마나 유사하게 예측하는지를 목적 함수(Loss Function)로 두는 것이다. Cross-Encoder 방식은 Bi-Encoder 방식에 비해 유사도 판단 성능이 좋기때문에 Teacher로서 활용되기도 한다.
(대신 Cross-Encoder 방식은 속도가 느리다. Cross Encoder와 Bi-Encoder 방식의 차이)
여기에 추가로 instruction 튜닝까지 실시하였는데, instruction 데이터는 "Improving Text Embeddings with Large Language Model"에서 밝힌 ChatGPT4 생성 데이터를 그대로 활용하였다.
Instruction(지시문)가 포함된 문장들을 학습하였으므로 instruct 튜닝 모델이라 표현한 것 같다.
모델의 성능은 multilingual-e5-large-instruct > multilingual-e5-large 이다.
[Data]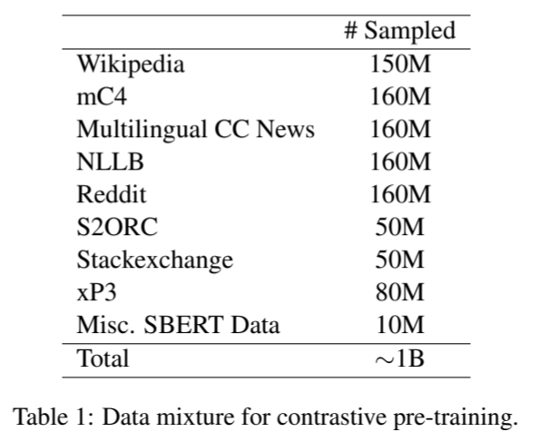

Unsupervised Constrastive 러닝때 활용된 데이터, 다양한 다국어 기반으로 데이터를 수집 및 학습에 활용


Supervised Contrasitive 러닝때 활용된 데이터. 다국어 데이터는 MIRACL과 Mr.TyDi만 해당됨.
[Evaluation]
이 논문에서는 영어 능력에는 MTEB를, 다국어 능력에는 MIRACL 벤치마크의 Testset를 활용하여 모델을 평가했다.
MTEB는 임베딩 모델계(?)에서 유명한 벤치마크이므로 소개를 생략한다.
MIRACL은 22년 오픈된 다국어 검색 능력 평가용 벤치마크로 약 18여개의 언어에 대한 검색 능력을 평가한다.
(16+2로 2개는 hidden language이다)
해당 데이터셋에는 한국어도 포함된다. 검색 능력 평가이기에 Metric으로는 nDCG와 Recall을 활용하였다.
MTEB와 MIRACL 스코어 
MIRACL 데이터셋 언어 728x90'AI 논문 리뷰' 카테고리의 다른 글