-
논문 리뷰) RoBERTa: A Robustly Optimized BERT Pretraining ApproachAI 논문 리뷰 2024. 6. 17. 20:55
본 글은 [Open-Up] 오픈소스 소프트웨어 통합지원센터로부터 지원받아 작성하였습니다.
RoBERTa는 모델 명에서 밝혔듯이, BERT의 사전학습 방식 일부를 변경하여, '최적화'를 꾀하고자 한 모델이다.
제안자는 BERT가 Undertrained 되었다고 주장한다.
그리고 BERT의 아키텍쳐를 따르되, 몇가지 학습 방법론을 바꾸어, SOTA를 달성했다.
(그러나, 실제로는 RoBERTa가 꼭 BERT보다 낫다고 볼수 없으며,
Base 모델을 RoBERTa/BERT 모두 취하여 실험하는 경우도 많다)
그럼에도 불구하고, BERT 계열의 대표적인 Base 모델이기에 상식(?)으로나마
알아두면 좋을 것이라 생각하여 리뷰를 진행하였다.
총평 :
BERT에서 제안한 학습 방법보다 더 잘 학습시킬 수 있는 학습 방법을 제안 = RoBERTa
4개의 주요 학습 방식 변경사항 (제안자는 논문에서 학습 방법을 Recipe라고 표현)
1. 더 큰 Batch Size
2. NSP(Next Sentence Prediction) 학습 삭제
3. 더 긴 문장으로 학습
4. MLM에서 Mask를 다이내믹하게 변경
추가적인 제안점
+) 거의 모든 설정을 BERT와 동일하게 하되,
peak learning rate과 number of warmup steps 등의 Scheduler를 조금 변경함.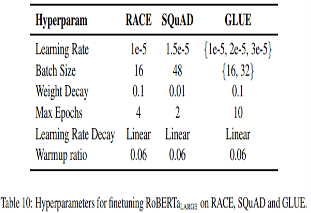

+) 데이터(문장)에 대해 짧은 문장을 랜덤하게 주입하지 않았고, 문장 길이를 줄이지 않았으며,
모든 길이로 적합하게 들어갈 수 있는 문장들만으로 학습을 진행하였음.
+) 기존의 BERT는 character level의 BPE를 사용하였음.
RoBERTa는 추가 전처리나 토크나이징 없이 larger byte-level BPE로 학습을 진행한 것이 특징.
Byte level BPE는 몇 개의 태스크에서 성능이 떨어진다는 단점이 있지만,
성능 하락폭이 크지 않고 universal 인코딩의 장점이 있다고 판단하여
본 연구에서는 Byte level BPE를 적용하였다고 함.
1. Dynamic Mask (Dynamic MLM)
기존의 BERT는 데이터 전처리 과정에서 한번만 마스킹을 시행한다.
그리고 같은 mask를 계속 적용하게된다. 즉 single static mask이다.
이렇게 각 에포크마다 같은 마스크가 적용되는 것을 방지하기 위해서,
학습데이터를 10번 복제하되, 10개의 각기 다른 mask를 적용한다.
이렇게 되면, 40 에포크 동안 각 시퀀스(문장)는 같은 마스크를 4번만 적용하게 되는 셈.
(static이었다면, 40번을 똑같은 mask 적용)
Static Mask와 Dynamic Mask의 성능 차이
2. NSP 학습 삭제
제안자는 NSP의 효용성에 대해서는 의문이 많았다.
그래서 여러 가자의 set를 통해 모델 학습을 진행해보았다
NSP loss를 사용하지 않았을 때 하위 태스크의 성능이 비슷하거나 조금 개선되었음을 확인하였고,
NSP 학습을 수행하지 않는 것으로 결정하였다.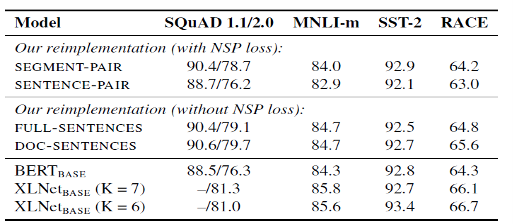
NSP loss를 사용하지 않았을 때의 성능 개선
3. 더 큰 Batch Size로 학습
큰 Batch Size로 학습하는 것은 Perplexity를 개선하고 정확도를 올린다.라고 주장함.
또한 큰 Batch Size가 분산 데이터 병렬 학습을 통해 병렬화하기 더욱 쉽다고 함.
Batch Size에 따른 Perplexity 개선
4. 더 긴 문장으로 학습 (input token size = 512)
짧은 문장을 랜덤하게 주입하지 않았고
문장 길이를 임의로 줄이지 않았으며,
길이가 적합하게 들어갈 수 있는 문장들만 학습을 수행하였다.
5. larger byte-level BPE를 사용
기존의 BERT는 character level의 BPE를 사용했다.
RoBERTa는 추가 전처리나 토크나이징 없이 larger byte-level BPE로 학습을 진행하였다.
Byte level BPE는 몇 개의 태스크에서 성능이 떨어진다는 단점이 있지만,
성능 하락폭이 크지 않고 universal 인코딩의 장점이 있다고 판단하여 본 연구에서 Byte level BPE를 적용하였다.고 한다.
위와 같은 방법으로 만든 모델이 바로 RoBERTa이다.
- 동적마스킹(dyamic masking),
- NSP loss를 사용하지 않는 FULL - SENTENCES,
- 큰 미니 배치(mini-batches)
- larger byte-level BPE를 적용하였다.
이를 통해, 아래 표처럼 GLUE 벤치마크에서 BERT 대비 압도적인 성능을 보였다.
728x90'AI 논문 리뷰' 카테고리의 다른 글