-
논문 리뷰) ReAct : SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELSAI 논문 리뷰 2024. 6. 11. 00:39
ReAct 는 22년도에 나온 Prompt 기법이다.
논문의 내용은 길지만, 핵심 내용은 간단하다.
ReAct = Reason + Act
= 추론 + 실행즉 ReAct란, 추론의 'CoT'와 실행의 'Action(검색 등)'을 조합하여
답변의 신뢰성과 추론의 능력을 키우고자 의도한 기법이다.
Prompting Method를 아래와 같이 4가지 방법으로 구분할수 있다.
- Standard Prompt
- Reason-only(CoT, Chain of Thought) : 즉, 추론 only
- Act-only : Action과 Observation(관찰) only
(action은 인터넷이나 문서같은 외부 요소에 접촉하여 정보를 수집)
- ReAct : 추론과 Action/observation 모두 적용
Prompting Method 즉, Reason Only는 내부의 지식을 활용하고,
Act Only는 외부의 지식(ex. WebSearch)을 활용하는 것이다.
Reason-only 모델은 자체 정보가 부족할 경우, Hallucination에 의한 부정확한 정보를 출력할 수 있고,
Act-only 모델은 추론 능력 부족으로 외부 정보를 기반으로도 최종 답에 이르지 못하고 엉뚱한 대답을 할 수 있다.
Reason-only와 Act Only 의 단점
반면에 ReAct는 내부의 지식과 외부의 자원을 모두 활용하는 방법으로추론(CoT) 방식과 Action/Observation들을 기반으로
해석 가능하고 사실에 기반한 Trajectory로 답변을 찾아간다.
(거시적인 관점에서 볼때, ReAct는 내부의 지식과 외부의 자원을 활용하는 RAG의 상위 개념으로도 볼수 있을 듯하다)

ReAct 진행과정 예시 (CoT-SC => ReAct 방식) ReAct 진행 과정은 1) ReAct => CoT-SC과 2) CoT-SC => ReAct로 나눌 수 있는데,
CoT-SC => ReAct 방식의 경우
1. 답변을 위한 추론(Thought)의 과정을 거치고,
2. 외부 지식에 기반한 Action을 실행하고,
3. 외부 지식에 대한 Observation(관찰)을 진행한다.
4. 그리고 다시 위의 1, 2, 3 과정을 반복해가며 답변에 도달한다.
ReAct => CoT-SC 방식은 순서가 바뀌어 Action-Observation-CoT 순서이다.
( CoT-SC는 CoT Self-Consistency를 말한다.
Self-Consistency prompt는 CoT(Chain of Thought)의 연장선으로,
하나의 답변이 아니라 여러 개의 사고 과정을 생성하고 그 중 다수결로 최종 답변을 결정하는 방식이다.
즉, 퓨샷 생각의 사슬(few-shot CoT)을 통해 여러 번의 다양한 추론 경로를 생성하고, 가장 일관된 답을 선택하는 것.
이때 일관된 답이라는 것은 가장 많이 나온 답을 택하거나, 가장 자주 나온 추론 경로를 택하는 것을 말한다. )이와 같이 ReAct 프롬프트는 문제 해결을 위한 일련의 'trajectory'들로 구성된다고 볼 수 있다.
추론과 외부 지식 기반의 조합인 ReAct 방식은 높은 성능을 보였고,논문 발표 당시 몇몇 Task에서는 SOTA를 달성했었다.
※ Trajectory : Reasoning/Thoughts, Actions, Observation 등 기본 프롬프트 질문에서 이어지는 과정을 나열한 것으로, ReAct Prompting에서 few shot example로 제공하거나,
fine-tuning 진행 후 최종 질문을 하였을 때, 학습했던 Trajectory에 따라 추론-act-obs를 실행하도록 지시한다.
눈에 띄는 점으로는 ReAct와 Act 방법은 더 많은 훈련 단계(혹은 더 많은 훈련 데이터)에서 성능 향상이 확인되지만, Standard Prompt와 CoT 방법은 Fine-tuning 이후에 빠르게 저하된다는 것이다.
외부 지식 기반(RAG)의 강인성이 여기서도 확인되는 것 같다.
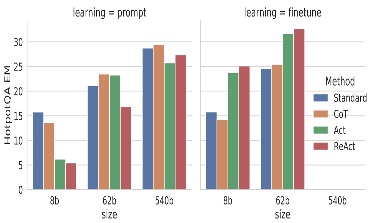

fine-tuning은 3,000개의 Trajectory를 사용하여 작은 언어 모델(PaLM-8/62B)에 학습을 실시하였는데,
Input용 질문/주장에 조건을 걸어, Trajectory(모든 생각, 행동, 관측)를 단계적으로 분리 실행할 수 있도록 했다.
728x90'AI 논문 리뷰' 카테고리의 다른 글
논문 리뷰) Llama 2 : Open Foundation and Fine-Tuned Chat Models (0) 2024.06.24 논문 리뷰) RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) 2024.06.17 논문 리뷰) Multilingual E5 Text Embeddings (mE5) (1) 2024.06.06 논문 리뷰) From Sparse to Dense_GPT-4 Summarization with Chain of Density Prompting (0) 2024.06.02 논문 리뷰) Extracting Interpretable Features from Claude 3 (0) 2024.05.28